HackIM Crypto5
31 Jan 2016 • LeanderDescription: Crypto5 is a 500 point challenge that was presented during HackIM in Jan 2016. The challenge presents a file that is encrypted with a RSA-Private key. Fortunately, we are provided a group of 49 public keys and one of them is the corresponding key for the private key …
Introduction
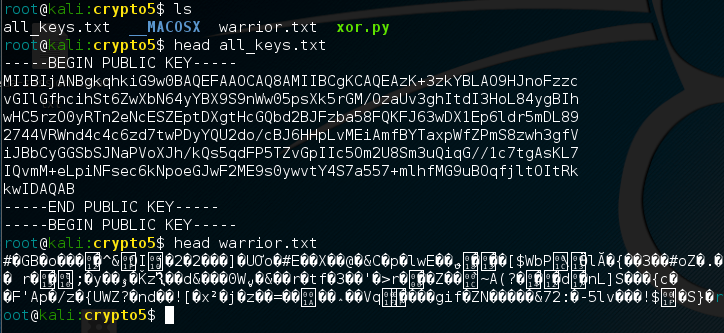
The Crypto5 challenge requires us to parse out public keys from a file all_keys.txt, which contains 49 different public keys. We are also given an encrypted file warrior.txt, which has information in it about the fighter described in the problem. We are fortunate enought to know that the corresponding public key IS included inside the 49 keys.
Solving the Problem
The first problem we have to solve is parsing out each one of the keys inside the file. We can see that each public key is formatted with a header, text in the middle, and a footer.
-----BEGIN PUBLIC KEY-----
MIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEApnEK4IQqzhdpkeGS5j8w
PONTfe3gLjHNPW2bL2i+fHZirviYTux1reOofqft3wfzEAZ2mDqbfzcHu6gxNkT4
7Fk6Tiyc/x8M1Un6nHFEao/GuwPqb48lr60xY5N7aYqB6z/FFAUboNNwmZK5DO+X
zrFzbVE021MScJEuCHfK1ogUYo6IhMcJAYDtgZ8HWqnj1mo/WqGvnwzf+iTtoKna
6vIsZ7PTEzQooI1J0gogos+iGZ/PGdMgQgK5DxthbcKQpuVO6U7aUeQPqfXZ89k6
SATmRq0k0I8Flbe07DKuC417WaNSNoM6ydPiT6c+yo2YS6OGPxbBEtoDreO4Jsxz
UwIDAQAB
-----END PUBLIC KEY-----Parsing the public keys
So first, I opened all_keys.txt in read-only mode. Next, I read the entire contents of all_keys.txt. Last, I used split() to separate each line using the carriage return as the delimiter. Then split()’s list is stored inside a variable so that I can operate on it later.
Since I know that each public key is 9 lines long, I can create a quick for loop that will put the public keys back together from the list. I piece the public keys back together using a modulus of 9 and also re-insert the carriage returns I had removed with split(). Last, I write them to a separate file so I can use them for decoding and keep a file_list of each file that I create.
Decrypting or encrypting the ciphertext
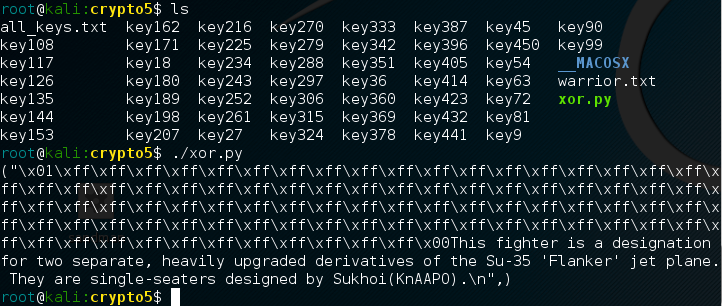
Now that I have the public keys separated out I can try using each key against the encrypted text file warrior.txt. Since I saved the name of each file I created inside a list, I can now iterate over that list without having to reach out into the current directory.
I do this by iterating over each item in the file_list I created. I open each public key, read the contents, and then import the contents as an RSA key using RSA.importKey().1 Next, I can encrypt the ciphertext and retrieve the plaintext results. I don’t want to read through 49 different results and manually search for the valid plaintext.
As a result, I found a useful python module called re. re contains methods which allow me to conduct searches based on regular expressions. I could then add a quick boolean if statement to validate whether or not the plaintext contained some common trigraphs and text I expected to be in the plaintext, such as fighter or warrior. re.search2 checked six different matches while ignoring the case 3 and if it found any matches it printed the results.
SCORE!
Originally, I tried to input several variations of Su-35 ‘Flanker’ jet plane, but after a quick Google search of Su-35 Sukhoi KnAAPO, I found the correct format for the flag.
Python script
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
#!/usr/bin/python
# regular expression library @ http://www.pythonlearn.com/html-007/cfbook012.html
# decrypt using RSA keys @ http://stackoverflow.com/questions/19548800/decrypt-using-an-rsa-public-key-with-pycrypto
from pwn import *
from Crypto.PublicKey import RSA
import re
rsa_pub_list = []
rsa_pub_list = open("all_keys.txt", "r").read().split("\n")
pub_key = ""
file_list = []
for i in range(1, len(rsa_pub_list)):
if i%9 !=0:
pub_key += rsa_pub_list[i-1] + "\n"
else:
pub_key += rsa_pub_list[i-1]
write("key"+str(i), data=pub_key)
file_list.append("key"+str(i))
pub_key = ""
ciphertext = open("warrior.txt", "r").read()
for s in range(len(file_list)):
key = RSA.importKey(open(file_list[s], "r").read())
plaintext = key.encrypt(ciphertext, 0)
if re.search('the|and|but|plane|fighter|warrior', str(plaintext), re.I):
print plaintext
Endnotes
-
There is an RSA module which allows you to directly use the methods of an RSA key object. More can be found on this module here ↩
-
re.search(pattern, string, flags=0)Scan through string looking for the first location where the regular expression pattern produces a match, and return a corresponding MatchObject instance. Return None if no position in the string matches the pattern; note that this is different from finding a zero-length match at some point in the string. ↩ -
re.IPerform case-insensitive matching; expressions like [A-Z] will match lowercase letters, too. This is not affected by the current locale. ↩